eBPF-powered, frictionless MRI for your heterogeneous compute infrastructure
- Debug faster
- Maximize GPU
- Reduce cloud costs
The best GPU for your next project is the one you already have.
Zymtrace squeezes more FLOPs from your infrastructure.
Profile-guided, agentic optimization for AI workloads.
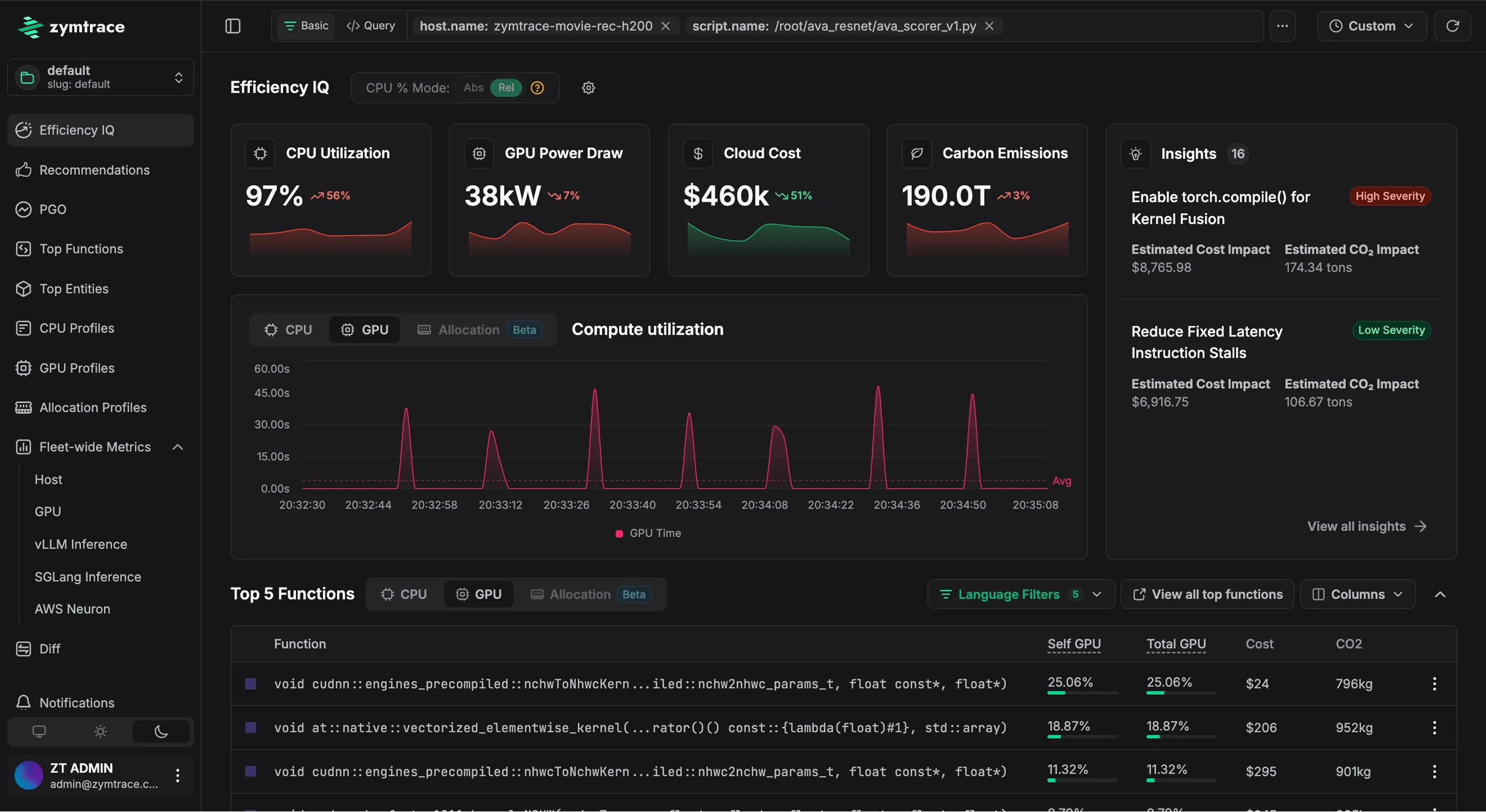

Maximize Tokens Per Dollar
Improve throughput, reduce latency, and lower cost-per-token across your inference fleet. Correlate token-level performance metrics with CPU and GPU profiles to pinpoint exactly what's stalling your inference engines.
 SGLang
SGLang  Dynamo-triton
Dynamo-triton Powering Efficient AI
Distributed training bottlenecks compound fast. Identify performance bottlenecks across GPUs and AI accelerators by correlating hardware profiles with the CPU dispatch paths driving them, surfacing AllReduce stalls, memory transfer saturation, and batching inefficiencies. Works with NVIDIA CUDA, AWS Inferentia, PyTorch, JAX & Rust.
One zymtrace agent to zym them all!
Drop in zymtrace agent and identify the most expensive lines of code across your entire fleet —your code, third-party libs, interpreted or native, running on CPU or GPU. If it's using cycles, we help you improve its efficiency.












Reduce mean-time-to dopamine
Most profilers throw flamegraphs at you and expect you to decode them. zymtrace's "Efficiency IQ" tells you exactly what's happening and shows you precisely what to do about it.
How it works



zymtrace is OpenTelemetry compliant, including support for OTEL resource attributes.
The zymtrace team were part of the team that pioneered, open-sourced, and donated the eBPF profiler to OpenTelemetry. With zymtrace, we’re extending that same low-level engineering excellence to GPU-bound workloads and building a highly scalable profiling platform purpose-built for today’s distributed, heterogeneous environments — spanning both general-purpose and AI-accelerated workloads.
support@zymtrace.com
zymtrace runs entirely on-premise. 5 minutes is all you need to get it up and running.
TRY IT NOW

